Deploy & Scale AI Models with Amazon SageMaker: A Comprehensive Guide
Introduction
In today’s AI-driven landscape, deploying and scaling machine learning models efficiently is as crucial as developing them. Amazon SageMaker has emerged as a powerful platform that simplifies this process, offering a comprehensive suite of tools designed to streamline the entire machine learning lifecycle. This blog post will guide you through deploying foundation models, specifically focusing on how to efficiently deploy and scale models like Gemma 2-2B using Amazon SageMaker.
The Anatomy of SageMaker Model Deployment
Amazon SageMaker provides multiple paths for model deployment, each catering to different requirements:
- Real-time Inference - For applications requiring immediate responses
- Batch Transform - For processing large datasets offline
- Serverless Inference - For intermittent workloads with cost optimization
- Asynchronous Inference - For long-running inference requests
Let’s explore how to deploy a foundation model using real-time inference, as shown in the screenshots.
Deploying Gemma 2-2B Model Using SageMaker
From the images, we can see a step-by-step process of deploying Google’s Gemma 2-2B model on SageMaker. Here’s what the workflow looks like:
Step 1: Prepare Your Environment
SageMaker Studio provides a comprehensive development environment with JupyterLab integration. As seen in the screenshots, you can create notebooks and run simple code:
1
print("hello world")
SageMaker Studio also offers multiple kernel options including Python 3, Glue PySpark, Glue Spark, SparkMagic PySpark, and SparkMagic Spark, allowing you to choose the right environment for your workload.
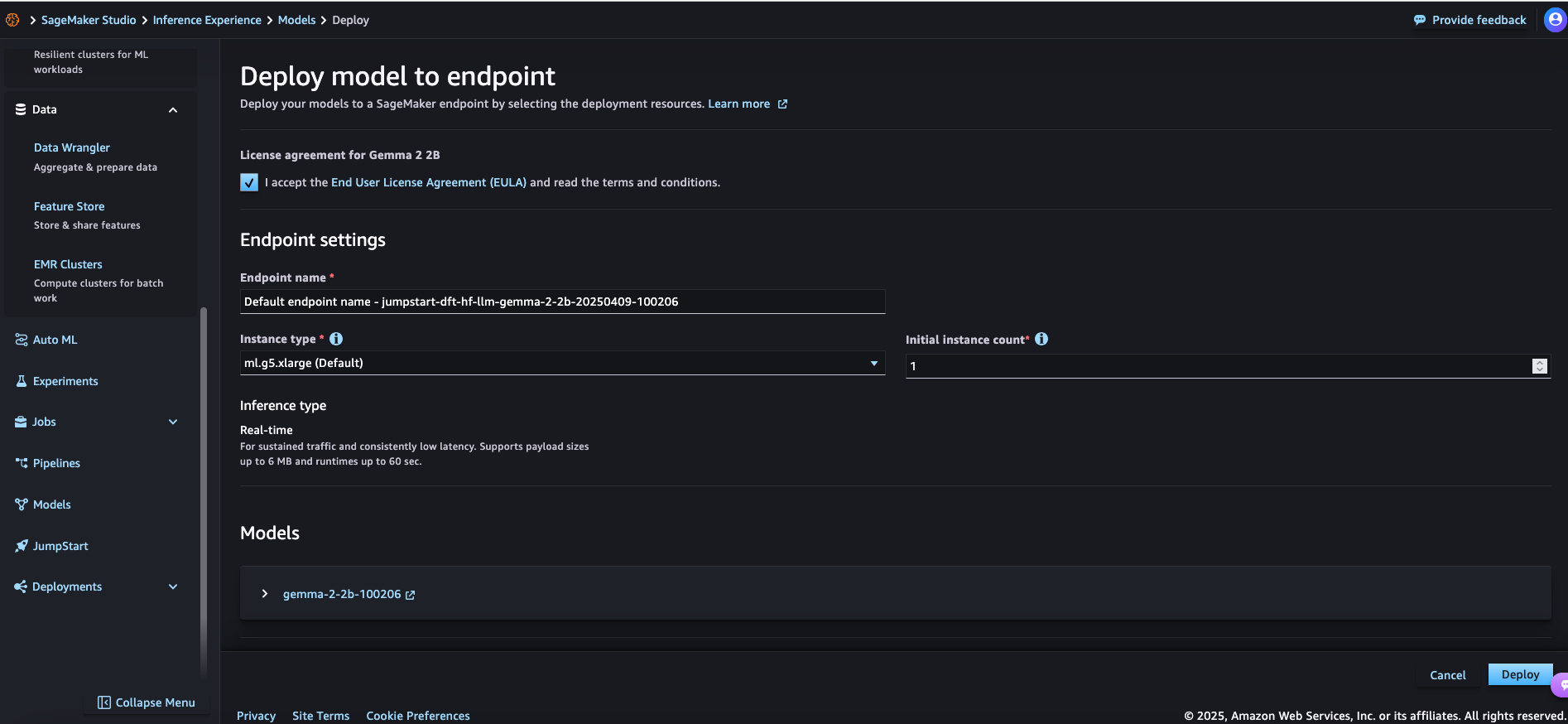
Step 2: Configure Your Model Deployment
When deploying a model, you need to configure several settings:
- Accept the license agreement - For foundation models like Gemma 2-2B, you need to accept the End User License Agreement (EULA)
- Endpoint settings:
- Endpoint name:
jumpstart-dft-hf-llm-gemma-2-2b-20250409-100206 - Instance type:
ml.g5.xlarge(Default) - Initial instance count: 1
- Inference type: Real-time (for sustained traffic and consistently low latency)
- Endpoint name:
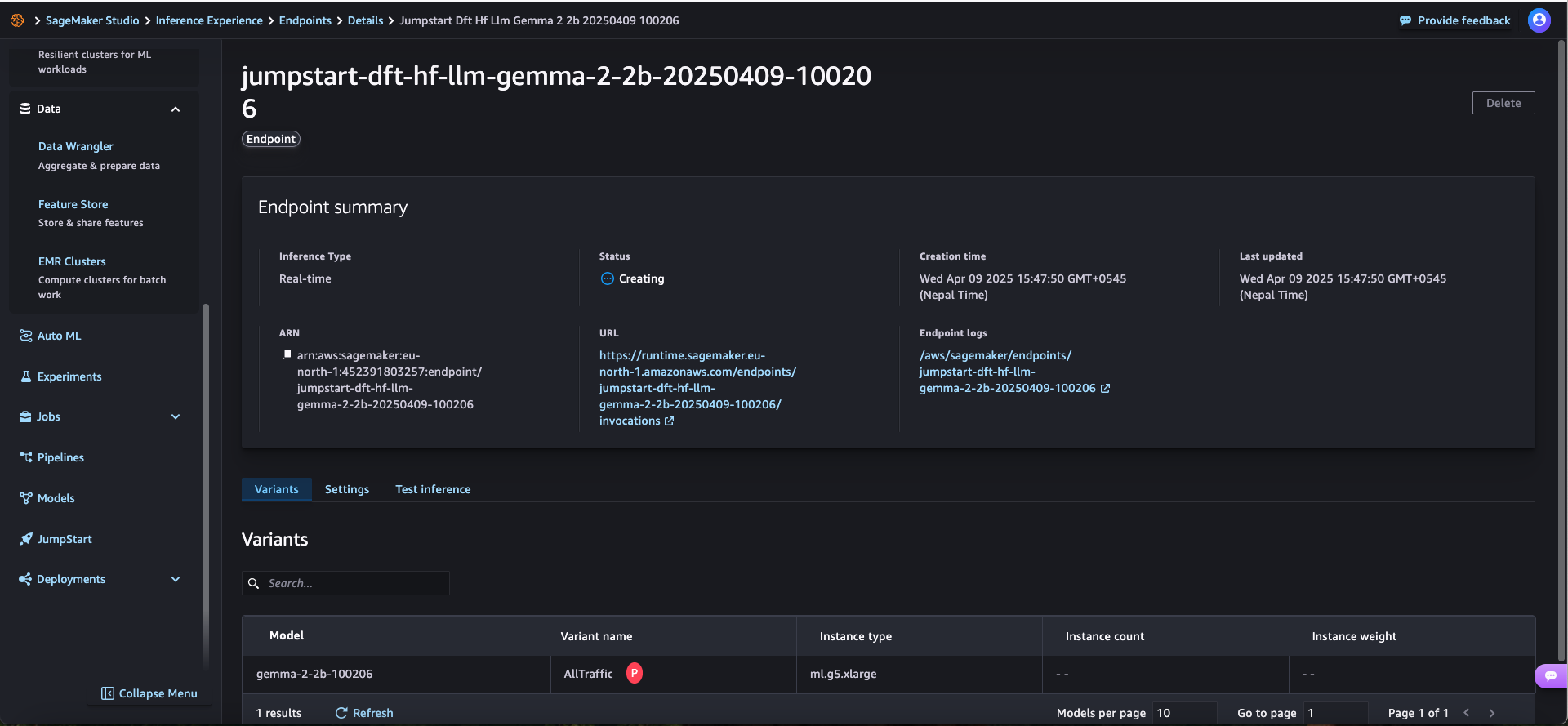
Step 3: Monitor Deployment
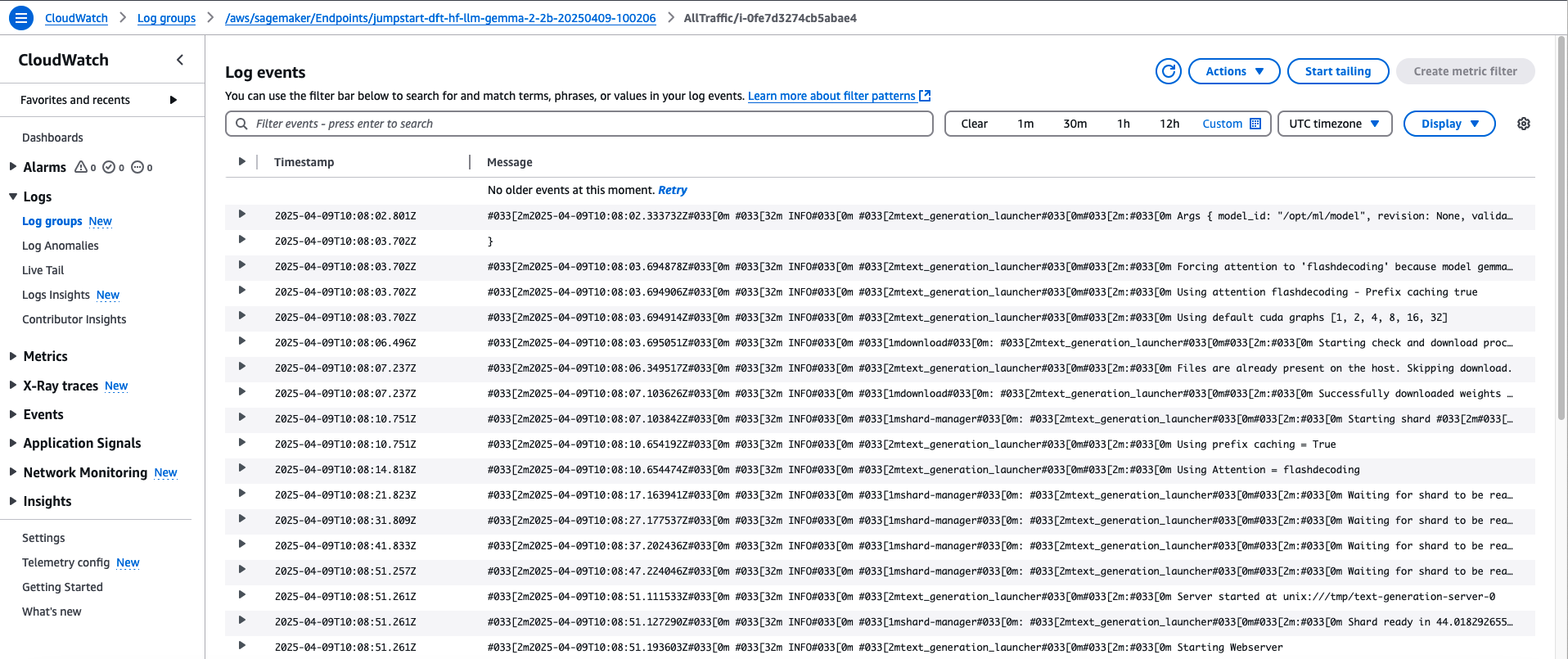
Once deployed, you can monitor the endpoint status through CloudWatch logs. From the screenshots, we can see the logs showing:
- Model downloading and initialization
- Using flashdecoding with prefix caching
- CUDA graph configuration
- Successful model weights download
- Sharded configuration waiting for completion
- Web server initialization
The deployment status will show “Creating” initially, then change to “InService” once the endpoint is ready to accept inference requests.
Scaling Your Model Deployment
SageMaker offers several ways to scale your model deployments:
Auto Scaling
SageMaker supports automatic scaling of endpoints based on workload, allowing you to:
- Configure scaling policies based on metrics like invocation count, latency, or CPU utilization
- Set minimum and maximum instance counts
- Define scale-in and scale-out behaviors
Model Variants
As shown in the endpoint details screen, you can deploy multiple variants of the same model:
- Different instance types for different performance requirements
- Multiple versions of the same model for A/B testing
- Custom resource allocation through instance weighting
In the example, we can see the “AllTraffic” variant using ml.g5.xlarge instance type.
Integration with JupyterLab
SageMaker Studio provides seamless integration with JupyterLab, allowing you to:
- Develop and test your machine learning code
- Prepare data for training and inference
- Deploy models directly from your notebook
- Test inference against deployed endpoints
The screenshots show a JupyterLab environment with a simple “hello world” test, but you can use it for much more complex ML workflows.
API-Based Model Invocation
Once your model is deployed, you can invoke it using the SageMaker Runtime API:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import boto3
import json
# Create a SageMaker runtime client
runtime = boto3.client('sagemaker-runtime')
# Define the payload
payload = {
"inputs": "Write a short poem about machine learning",
"parameters": {
"max_new_tokens": 128,
"temperature": 0.7,
"top_p": 0.9
}
}
# Invoke the endpoint
response = runtime.invoke_endpoint(
EndpointName='jumpstart-dft-hf-llm-gemma-2-2b-20250409-100206',
ContentType='application/json',
Body=json.dumps(payload)
)
# Parse the response
result = json.loads(response['Body'].read().decode())
print(result)
This API-based approach allows you to integrate SageMaker-hosted models into your applications, microservices, or other cloud resources.
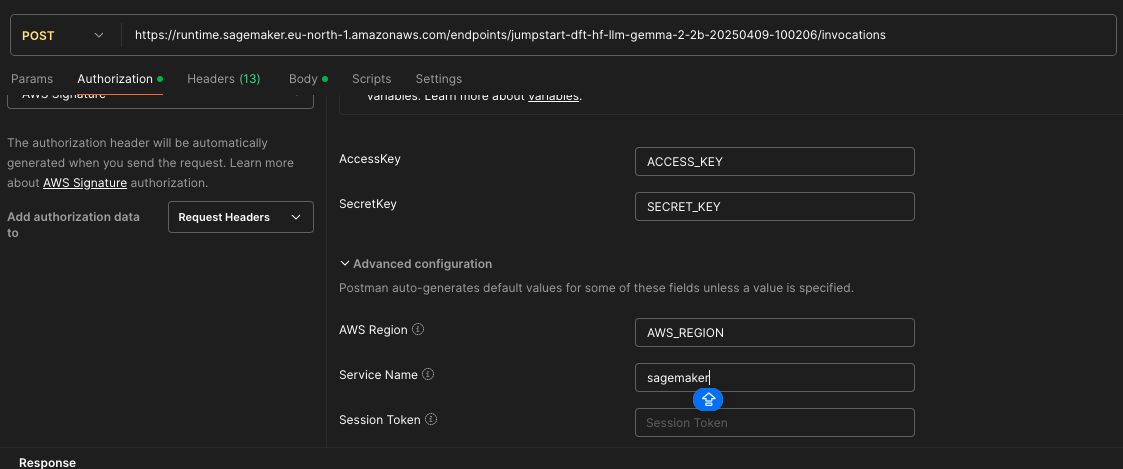
API call for model prediction
Setup Authorization
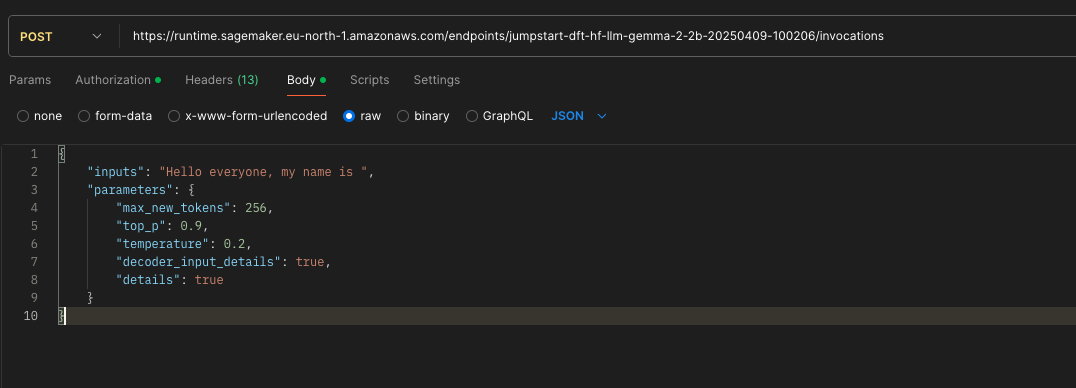
Pass JSON raw data as POSt route in model endpoint invocations to get prediction
Foundation Models Available on SageMaker
Amazon SageMaker supports a wide variety of foundation models, including:
- Large Language Models:
- Anthropic Claude (various versions)
- Meta Llama 2 and Llama 3
- Mistral
- Google Gemma (as seen in our example)
- Amazon Titan
- Multimodal Models:
- Stable Diffusion
- DALL-E
- Amazon Titan Image Generator
- Anthropic Claude Multimodal
- Embedding Models:
- BERT variants
- Sentence transformers
- Amazon Titan Embeddings
Advantages of Using Amazon SageMaker for Model Deployment
Based on the screenshots and SageMaker capabilities, here are some key advantages:
- Simplified Deployment - Point-and-click deployment of complex models
- Infrastructure Management - Automated handling of underlying infrastructure
- Cost Optimization - Various instance types and auto-scaling to control costs
- Monitoring and Observability - Integrated CloudWatch monitoring
- Security and Compliance - IAM integration, VPC support, and encryption options
- Flexibility - Support for custom containers and bring-your-own-model scenarios
- Integrated ML Lifecycle - Seamless transition from experimentation to production
- Pre-trained Foundation Models - Quick access to state-of-the-art models
Best Practices for SageMaker Deployments
To get the most out of your SageMaker deployments:
- Right-size your instances - Choose appropriate instance types for your workload
- Implement auto-scaling - Configure scaling policies based on expected traffic patterns
- Monitor performance - Use CloudWatch to track invocations, latency, and errors
- Optimize costs - Consider serverless inference for intermittent workloads
- Version control your models - Use model registries to track model versions
- Test thoroughly - Validate model performance before production deployment
- Implement CI/CD pipelines - Automate the deployment process for consistency
Conclusion
Amazon SageMaker significantly simplifies the deployment and scaling of machine learning models, including complex foundation models like Google’s Gemma. By providing a comprehensive platform that handles infrastructure management, scaling, and monitoring, SageMaker allows data scientists and ML engineers to focus on creating value rather than managing infrastructure.
The deployment process demonstrated in this post shows how quickly you can go from model selection to a production-ready API endpoint. Whether you’re deploying a simple sentiment analysis model or a large language model like Gemma 2-2B, SageMaker provides the tools and capabilities to do so efficiently and at scale.
As AI continues to evolve and more foundation models become available, platforms like SageMaker will play an increasingly important role in making these technologies accessible and manageable in production environments.
Resources
- Amazon SageMaker Documentation
- Amazon SageMaker JumpStart
- Foundation Models in SageMaker
- SageMaker Auto Scaling